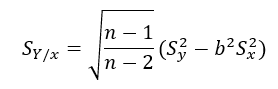Al realizar un estudio de datos es frecuente que se tenga que descubrir y analizar la dependencia que tiene un valor de una variable con respecto a al valor de otra variable.La relación que tienen las variables puede ser:
Método de mínimos cuadrados: permite minimizar al máximo el error cuadrado o la suma de cuadrados.
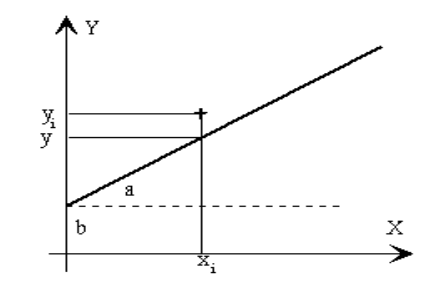
La dependencia entre las variables se representa como una línea recta, que puede representarse por la ecuación: y= a + bx.
Se considera que la variable “x” es la variable independiente o regresiva y se mide sin error, mientras que “y” es la variable respuesta para cada valor específico xi de x; y además Y es una variable aleatoria con alguna función de densidad para cada nivel de x.
Es necesaria determinar los valores de a y b para establecer el comportamiento lineal de la recta. Cada par de números (x,y) que satisfacen la relación y = a + bx estará sobre una línea recta cuando se grafique.
b = la pendiente de una línea, expresa el cambio en “y” asociado con el incremento en una unidad de “x”.
a = el intercepto, es la altura o nivel de la línea cuando “x” es igual a cero, esto es, el valor de “y” cuando la línea cruza el eje de las “y ́s”
La pendiente y el intercepto de cualquier línea recta pueden encontrarse a partir de dos puntos sobre dicha recta.
Para calcular el valor de “b” se utiliza la fórmula:
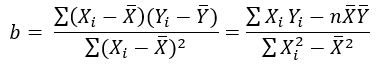
Los valores de estas fórmulas se toman de hacer diversos cálculos a partir de los datos iniciales, para facilitar este cálculo podemos realizar una tabla.Para calcular el intercepto se utiliza la fórmula:
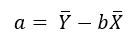
El análisis de regresión y correlación es una estimación de los valores que puede tomar la variable dependiente con base en un valor de probabilidad, esto porque al trabajar con sistemas biológicos no siempre se obtendrán los mismos resultados luego de realizar un experimento.
Los supuestos del análisis de Regresión:
Los valores de la variable independiente X son fijos, a X se le llama variable no aleatoria. Para cada valor de X hay una subpoblación de valores de Y, y cada subpoblación de valores de Y debe estar normalmente distribuida (Normalidad).
Las varianzas de las subpoblaciones de Y deben ser iguales (Homocedasticidad).
Las medias de las subpoblaciones de Y están todas sobre una recta (linealidad).
Los valores de Y son estadísticamente independientes; es decir, los valores de Y correspondientes a un valor de X no dependen de los valores de Y para otro valor de X (Independencia).
Las subpoblaciones a las que se hacen mención representan la variación de los valores que puede tomar la variable dependiente para cada valor de X, conociendo esta variación podemos saber con qué nivel de confianza se realizan las predicciones.
El error de estimación representa la diferencia entre el resultado estimado y el resultado real (valores muestrales), es decir, qué tan alejada está la ecuación calculada de los valores reales. Se representa por la siguiente fórmula: